近期有些比赛,涉及到提供用户的app行为数据,包含广告(或文章、视频等内容推荐)的点击率数据。
要求预测客户点击广告的概率。
部分学习资料:
推荐收藏!推荐系统技术发展综述 - 知乎 (zhihu.com)
一文详解搜广推 CTR 建模 - 知乎 (zhihu.com)
Spark机器学习进阶实战: 11.4 新闻App点击率预估实践(训练样本,关键词) - AI牛丝 (ai2news.com)
万字长文经典-文本特征处理的四类方式 - 知乎 (zhihu.com)
学习总结:
目标是构建一个二分类模型,方法是先构建一个宽表。
宽表目标字段为“是否点击”,
宽表特征字段:用户的信息、商品的信息、场景的信息以及端侧的信息
“用户的特征标签”(性别、年龄、爱好、搜索词之类的)
“广告的特征标签”(频道、来源、标题、内容等)
当然这样构建的CTR模型还有很大的优化空间,可以对特征进行交叉(如广告和广告位交叉),也可以考虑加入广告点击率的反馈统计,还可以考虑使用广告标题和搜索词的语义特征,这里不再详细介绍。
模型的优化过程实际上是对数据的一个理解过程,其中大量的工作是分析样本并构建有效特征,论文《Context-aware Ensemble of Multifaceted Factorization Models for Recommendation Prediction in Social Networks》详细介绍了对于数据集进行会话分析、数据清洗、特征构建、用户建模的方法,有兴趣的读者可以阅读学习。
特征 Embedding
我们的 pCTR 的特征从分布类型看,分为连续类型、离散类型(包含 ID 类型)、序列类型。从特征主体划分,可以分为 User 特征、Item 特征、Scene 特征、交叉特征。
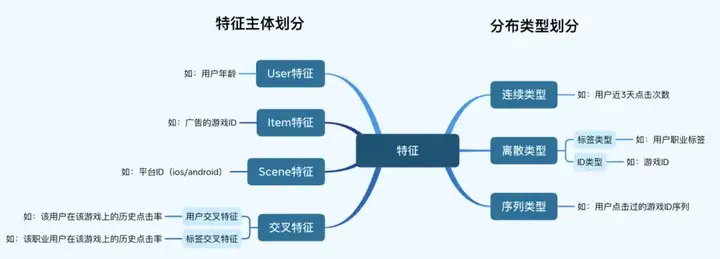
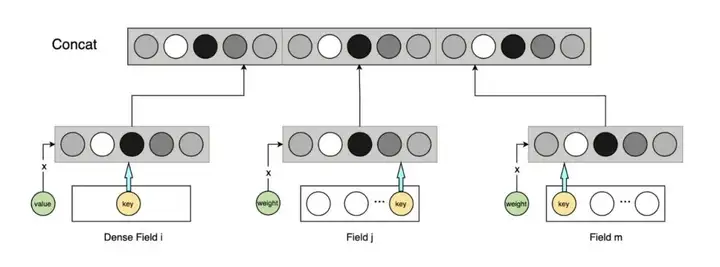
对于每一个特征,我们都会先将其 embedding 化,然后乘上该特征的 value 或 weight(对于连续特征是 value,对于离散标签特征是标签权重 weight)。最后可以将其 concat 到一起,或单独通过其他网络结构。
特征预处理
有些特征的特点是分布偏态十分严重,且极差极大。如“用户近 90 天游戏付费金额”,大多数用户该特征都是 0,但是极少量用户的付费金额可能达到数十万。这种情况如果直接让深度模型学习,会导致模型很难收敛,就算收敛了模型效果也大打折扣。详见 一文详解搜广推 CTR 建模 - 知乎 (zhihu.com)
特征交叉
- 人工交叉
模型自动交叉的优点是不需要人工参与,可以自适应根据数据集来进行交叉。但这对于复杂的交叉关系需要极其大量的数据来进行训练,这是不现实的。人工交叉可以讲一些主观认为有价值的交叉特征直接提炼出来,不需要模型去学习,降低了模型学习的难度。
现阶段我们开发了 30+个“用户交叉特征”和 80+个“用户属性标签交叉特征”,用户交叉特征诸如“该用户在该游戏上的历史点击率”、“该用户在该媒体上的历史点击数”等,描述每个用户对每个广告的交叉特征;用户属性标签交叉特征诸如“该职业用户在该游戏上的历史点击率”、“该年龄段用户在该广告模板上的历史点击率”等,描述一个用户属性标签下所有用户对每个广告的交叉特征。
- 模型结构交叉
在行业内中已经有了大量关于特征自动交叉的研究成果,从 FM 到 FFM 再到 DeepFM,以及后续基于 Attention 的各种交叉变种,本文在这里就不再赘述。我们在模型结构交叉上有过几个版本的迭代:DeepFM、AutoInt 变种、DCN 变种。
详见 一文详解搜广推 CTR 建模 - 知乎 (zhihu.com)
特征冗余共线
在特征中不可避免的会出现特征之间的共线性,比如“用户近 24h 的点击数”和“用户近 72h 的点击数”,又比如“用户在该媒体上的历史点击率”和“用户近 3 天历史点击率”,不可避免的会有较高的共线性。高度共线的特征会使模型很容易在局部最小值处提前收敛,而且可能会导致模型参数量增加,但没有增加有效的信息,从而出现过拟合现象。
针对这种情况,我们借鉴了《GateNet:Gating-Enhanced Deep Network for Click-Through Rate Prediction》中的方案,在模型内部添加一个 Gate 层,本质上是为每个特征增加了一个“可学习的权重”。
考虑到实际上在共线性的情况下,一个特征的权重不仅与自身有关,还与其他特征有关。所以我们采用 Bit-Wise Feature Embedding Gate 结构
序列建模
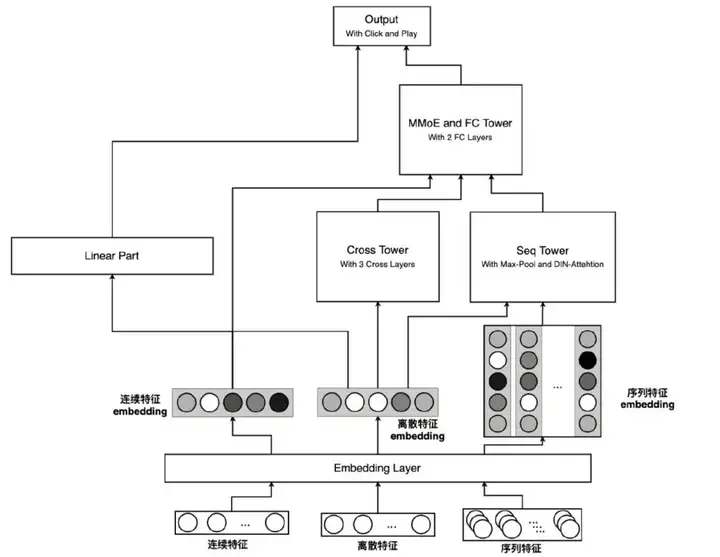
我们在特征方面还引入了序列类型的特征:用户点击游戏序列、用户点击游戏品类序列、用户点击创意序列、用户点击广告序列、用户点击计划序列、用户点击广告类型序列这 6 个序列。针对每个序列先对其 Embedding 化,然后分别进行 Max-Poolling 和 DIN-Attention,并最终进行 concat,作为序列建模层的输出。
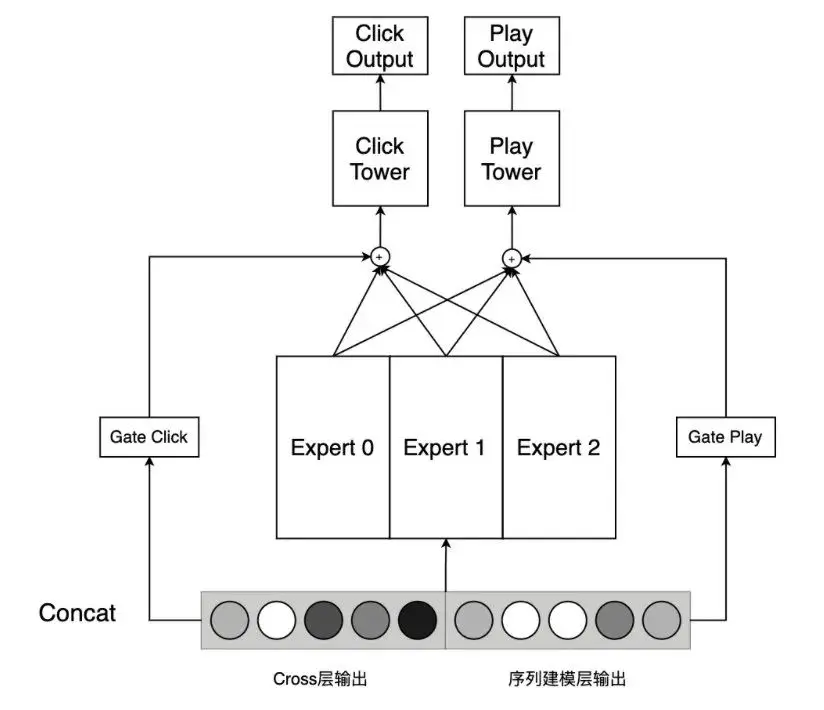
多任务建模
在不同的场景中,我们可以采用不同的辅助任务,来辅助 CTR 模型训练。如朋友圈广告中可以进行“点赞”、“评论”等交互动作。在联盟类流量的广告投放中,因为所对接的媒体类型繁杂,很难推行统一的“交互行为”。我们尝试利用预测视频播放的标签来作为辅助任务,视频播放标签分为:“未播放到 75%”、“播放至 75%到 100%之间”、“完成播放”、“其他”这四个标签,其中“其他”主要表示非视频类曝光。模型结构上,我们将 Cross 层的输出和序列建模层的输出进行 concat,然后经过一个MMoE层,后为两个任务分别接两个 FC 层形成子塔。
素材特征
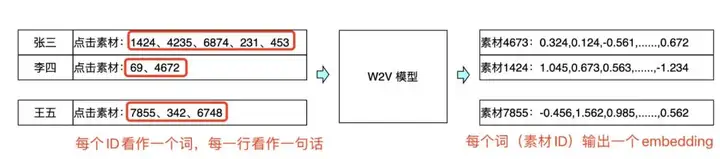
用户刷到广告后,与用户体验相关性最强的就是素材。我们也加入了一些素材的 Embedding 特征,我们尝试将单个用户近期点击过的素材 ID 看作一个集合,同处在一个集合中的素材 ID 看作是一次“共现”。这个关系与 NLP 中,一个句子中词的共现是类似的,只不过素材 ID 的共现中没有前后顺序的联系。所以我们建立了一个简单的 W2V 模型,根据素材 ID 之间的共现关系,学习每个素材 ID 的 Embedding,并将该 Embedding 加入到 pCTR 模型中,给模型的 AUC 稳定地带来了约 0.0003 的提升。
另外我们也尝试过对视频素材内容进行理解,从而提取视频素材的标签或Embedding,从而辅助 CTR 建模,目前取得了离线 AUC 提升 0.0015 的效果,这部分内容比较多本文不做详细介绍。
最终模型结构
模型校准
偏差是指模型对于整体数据集或部分数据集的预测结果,整体偏高或偏低。在广告系统中,我们不仅需要把最合适的广告排在前面,还需要精确计算这一次曝光的“价格”。所以对于广告系统中,偏差指标与衡量排序的 AUC 都很重要。如果偏差>0,说明我们多花了冤枉钱来买低质量曝光机会,如果偏差<0 说明我们损失了一些“物美价廉”曝光机会。这里我们的偏差定义为:
模型的偏差主要有以下 4 个来源:
- 训练样本采样
- 冷启动
- 数据分布迁移
- 模型收敛到局部最优解
所以我们在进行模型版本迭代时,尽可能不要以引入大量参数为代价,去追求细微的效果提升。这短期看是可以取得更好的效果,但长期看其实是给自己挖坑。
缩放校准公式
常用的校准方案 Isotonic Regression 和 Platt Calibration。但是本文主要想介绍另一种更简单的方案——在论文《Practical Lessons from Predicting Clicks on Ads at Facebook》中,作者采用了一种缩放公式来进行校准:

文章评论