最近工作上有相关需求,所以开始学习一下。
主要参考资料(传说中的“在线学习”):
目前搜索的纠错算法主要有哪些?各有什么优略性?请技术大牛给简单科普一下。 - 知乎 (zhihu.com)
策略算法工程师之路-Query纠错算法 - 知乎 (zhihu.com)
python | 高效统计语言模型kenlm:新词发现、分词、智能纠错 - 知乎 (zhihu.com)
1.1 什么是纠错算法
纠错算法,大多情况下指的是用于搜索场景下的一种算法,能够帮助用户纠正输入,从而更快的找到准确的答案。
2.2纠错算法三个步骤
纠错算法一般通过三个步骤完成从待纠错词→最优候选词的生成:
1、错误位置检测:通过混淆字典、语言模型等方法识别出输入文本错误位置;
2、候选词召回:通过相近词典、混淆词典等方法加编辑距离获得候选词;
3、召回排序:通过语言模型、词频或自定义规则(如最小编辑距离)等方法获得最优候选词
3.1中文方案
无监督方案:
1、基于字典的纠错(构建词典,如“火涡”→“火锅”,“美困” →“美团”)
2、基于规则的纠错(编辑距离+语言模型等)
有监督方案:
1、基于序列标注的纠错(序列标注用O标注正确词,S-1标注错误的词);
2、基于生成文本的纠错(seq2seq模型)
4.0 方案选择
1、实际上,我们会发现,有监督方案的开源数据集不够,而从日志中获取相关数据的难度又很大(其实还是需要很多人工的审核挑选工作);
2、前期最合适的方案,还是无监督的方法,可以基于规则的方案进行实现和优化;
3、以下实现主要针对中文方案。
4.1训练语言模型
1、kenlm这个语言模型工具实在太棒了,看过我上一篇新词发现(一)的朋友,会发现很熟悉,因为新词发现中的ngram计算也是用kenlm模型实现的,这时候我们后续会使用到kenlm的语言模型,进行困惑度计算;
2、具体的训练流程和困惑度计算原理可以参见:python | 高效统计语言模型kenlm:新词发现、分词、智能纠错;
3、训练完成后,我们可以获得kenlm的模型kenlm_model并且用kenlm_modle.score计算候选词的困惑度(ppl),得分从小到大,完成候选词的排序。
4.2 错误位置检测
1、这部分可以参照pycorrect开源代码中的错误检测部分,对每个字用滑动窗口采样,得到2gram和3gram的平均困惑度ppl_2和ppl_3,再求它们平均值,得到单个字的困惑度,然后再计算平均绝对离差(MAD),最终得到错误位置。
4.3 候选词召回
1、候选词的召回可以采用编辑距离,针对上一个步骤,对错误位置的字,进行增加、删除、替换、旋转等操作获得;
2、这里分享一个比较好的形似词库,供大家参考SimilarCharacter;
3、根据上述步骤,可以获得候选词列表。
4.4候选词排序
1、最后使用训练好的语言模型进行困惑度计算并排序即可;
2、这里需要注意的是,如果需要将原词也加入困惑度计算,防止出现误纠的情况,如果未找到困惑度更低的词语,则可以直接返回原词;
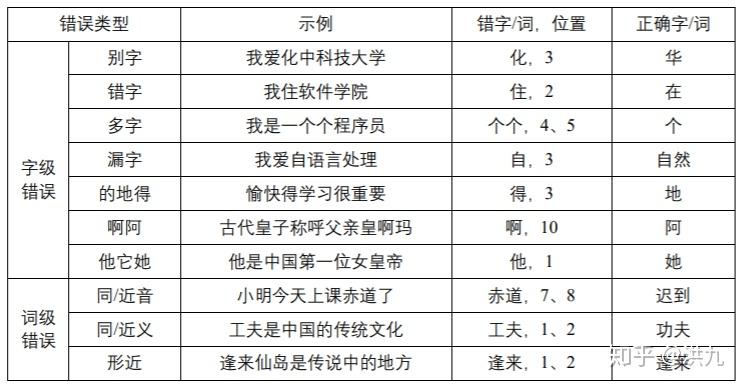
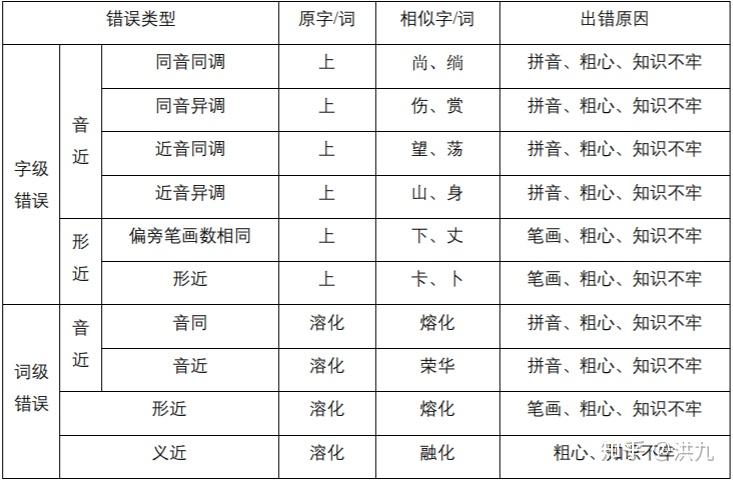
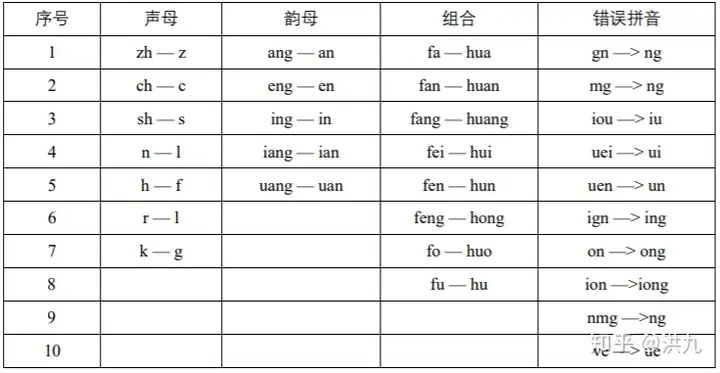
2.Query错误的原因
中文拼写出错的原因很多,主要与键盘的输入法有关,同时也与用户自身的方言 习惯以及知识的掌握程度相关。
1).拼音相关(相同读音、相同音节不同音调、相似音节相同音调、相似音节不同音调)
- 同音字 "度假"->"渡假" "芈月传"->"米月传" 配副眼睛-配副眼镜
- 模糊音 "福建"->"胡建" "听说"->"听所" "人力资源"->"人力支援" "牛郎织女"-"流浪织女" "因该"->"应该"
- 方言 "我系东北淫"->"我是东北人" "灰机"->"飞机"
2).字形相关
- 输入错误 "go语音"->"go语言"
- 形似错误 高梁-高粱
- 知识错误 "复兴地产 "->"复星地产" "广州黄浦"->"广州黄埔" 哈蜜”->“哈密”
3).语义相关
- 上下文不符 "配副眼睛"->"配副眼镜" "惊醒"->"警醒"
4).重复性错误
"在上上面"->"在上面"
3.Query纠错基本框架
随着NLP技术的发展,Query纠错策略也经过由简到繁的演化过程,不过整体来看Query纠错的基本原理类似于推荐系统中的"召回->排序"。在召回阶段,依据各种召回策略生成"原始Query"的若干"候选Query"集合;在排序阶段,依据语言打分模型筛选出最有可能的TopN个结果Query。如下图:

5.基于字典的Query纠错
构建一个常见错误的词表(例如"一旦"写成"一但"),如果匹配到错词,则给出正确意见。
简单、粗暴、好用!介绍完毕。
6.基于规则的Query纠错
算法效果如下:

算法流程如下:
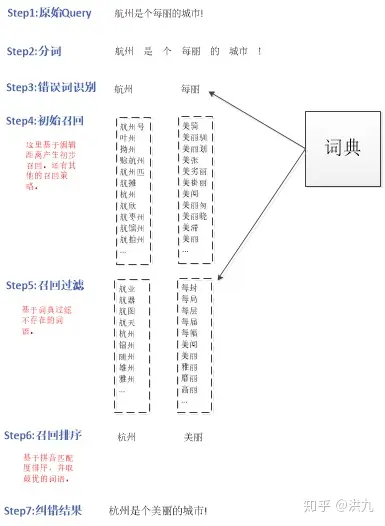
整个算法比较直观,但麻雀虽小五脏俱全,整个流程包含召回和排序两个阶段。在召回阶段,基于编辑距离召回错误词的候选修正词;在排序(Step6)阶段,依据候选词拼音与原词拼音的相似度确定最优候选词。算法比较简单,下面介绍其中几个需要注意的点。
1.错误检测
准确识别错误位置,首先可见降低时间复杂度,其次可以减少错纠(将原来正确的改错)。可以参考的错误识别方法:
- 字典匹配。切词后不在词典中的即认为是错的(本小节采用的策略)。
- 混淆字典。切词后如果在易混淆字典中则认为有可能出错。
- 易混淆拼音。如果拼音为易混淆拼音则认为有可能出错。
- 语言模型。某个字的似然概率值低于句子文本平均值。
- 机器学习分类模型。特征工程+ 分类模型(LR、Xgboost、DNN、LSTM+CRF、MLM-Bert等)。https://blog.csdn.net/weixin_39422563/article/details/106957654
- 单双向2gram。当前词与上下文组成的2gram频次很低(正确表述发生的频次要远远大于错误表述发生的次数),则认为有错。可参考算法流程如下:(略)
- 全认为错。即认为每个词都是错的。
至于选择什么样的策略要综合考虑对指标的影响,以"全认为错"为例,提高了召回率但FAR(错纠率)。参考论文:<<中文拼写检错和纠错算法的优化及实现>>。
2.编辑距离召回
在召回阶段中,利用编辑距离生成原词的候选词(Step4)。编辑距离(Minimum Edit Distance,MED), 由俄罗斯科学家Vladimir Levenshtein在1965年提出, 也因此而得名 Levenshtein Distance。通俗地来讲,编辑距离指的是在两个单词之间,由其中一个单词转换为另一个单词所需要的最少单字符编辑操作次数。编辑距离中,基于单字符编辑操作有且仅有三种:
- 插入(Insertion)
- 删除(Deletion)
- 替换(Substitution)
通常错误Query是由于用户多输、少输、错输导致的,正好对应了编辑距离的插入、删除、替换三种操作,而正确词可能包含在编辑距离操作生成的候选词中。因此扩大候选词召回范围,其中包括正确词的可能也就越高。召回阶段对整个策略的性能至关重要,除了编辑距离召回,还有其他多种候选词召回策略。
可以参考: NLP深入学习——拼写纠错(spell correction )_superbfiy的博客-CSDN博客
2. 词典过滤
为了减小算法的时间复杂度,在Step3和Step5中利用预先挖掘的词典做过滤,以减少后续不必要的操作。
3. 召回排序
如何从候选集中选出最合适的候选词是召回排序阶段要回答的问题。本算法中采用了一种非常简单的假设:候选Query拼音与原始Query拼音是相同或接近的。因此可以简单依据拼音匹配度筛选最优的候选Query,实际语料统计85%的错误是由于拼音导致 。
上面算法存在诸多问题:
- 召回策略比较单一(编辑距离召回),可能漏掉正确候选词。
- 在排序阶段没有考虑Query中词与词之间的前后依赖关系。在语言中,词与词之间不是孤立存在的,同一个词在不同的上下文中含义往往也是不同的。
- ...
上述算法的详细代码可以参考:
Autochecker4Chinese/AutoChecker4Chinese.ipynb at master · beyondacm/Autochecker4Chinese · GitHub

文章评论